Case study
Enterprise voice AI platform
Shipped a multi-tenant voice agent platform to enterprise production, with 1.2s median full-turn latency and GDPR-grade isolation across tenants.
Headline metric
1.2s
median full-turn latency
Stack
- TypeScript
- Node.js
- Express
- Next.js
- LiveKit
- Azure AI Foundry
- Python
Voice agents that ship to enterprise, not just demos.
The problem
An enterprise voice AI platform needed to do three things that most off-the-shelf stacks fail on at the same time: hold a natural conversation under one second per stage, isolate tenant data to GDPR standards, and slot into existing telephony and CRM without rewriting either. Demo-quality voice was not the bar. Production was.
The approach
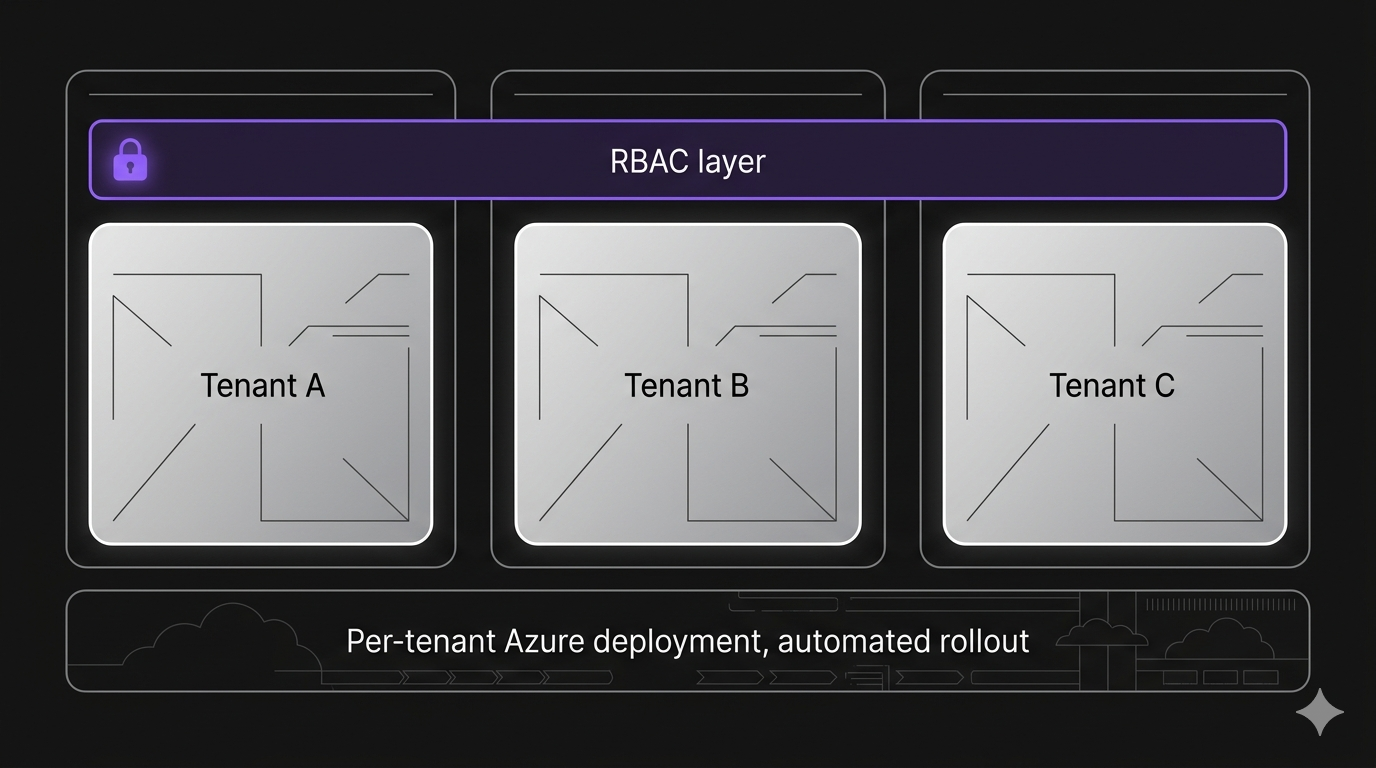
I architected the backend from zero with the founder, then led a small team of senior engineers through the build. The main platform is a Node.js and Express service in TypeScript handling business logic, RBAC, admin tooling, and tenant management. The voice agent runtime is a separate Python service on LiveKit handling realtime media and turn-taking, with Azure AI Foundry behind the LLM and retrieval calls. Tools and external integrations all run on a single shared runtime so the agent's context stays coherent across a call.
I enforced multi-tenancy end to end across the platform. Tenant onboarding is automated rather than a manual ops job, with a per-tenant Azure rollout I built in Python so each new customer is a repeatable pipeline. On top of all of this sits the RBAC layer I designed and built independently, so every action across the platform passes through a role and permission check before it reaches data or tools.
Tech decisions worth noting
- LiveKit over raw WebRTC. Realtime primitives and turn-taking are battle-tested, and the deployment model fit the security posture we needed.
- Azure AI Foundry for the LLM layer. Aligned with the cloud enterprise buyers already trust, which keeps procurement and security review tractable.
- TypeScript end to end above the agent runtime. Node.js and Express for the main platform, Next.js for the dashboard. One language for business logic, RBAC, admin, and UI.
- Python kept tight on the agent runtime and pipelines. Strongest agentic and RAG ecosystem for the voice layer, and the right fit for the deployment automation. Latency budgets held at the scale we needed.
- Docker everywhere. Same image, same behaviour, from local to staging to per-tenant production.
Outcome
- We shipped to enterprise production before contract end.
- The platform held ~1.2s median full-turn latency end to end (STT, LLM, TTS, VAD combined), with sub-second numbers on individual stages.
- The testing team load-tested the platform at roughly 10 concurrent tenants and verified isolation across data, runtime, and deployment.
- It met the enterprise security bar with the multi-tenant model and RBAC layer intact.
- I led the senior engineering team through delivery, then guided them after launch so they could own the platform once I rolled off.

What I learned
The hardest engineering for me was not the model layer. It was making the orchestration deterministic enough to debug. Voice agents fail in ways text agents do not: silence, partial speech, barge-in mid-tool-call, network jitter that looks like a user hanging up. Off-the-shelf eval tooling does not cover these failure modes yet, so a meaningful chunk of my engineering time went into closing that gap. That is what made the difference between a demo and something an enterprise will actually run.